Deep Learning: Do-It-Yourself!
Course introduction
Slides available at ai.honu.io.
Teaching assistants





Deep learning power
- Faster indexing with deep learning
- End-to-end speech recognition
- Music notes synthesis
- Limits and biases of supervised learning
- Unsupervised word translation
- DOOM AI
Faster indexing with deep learning
A neural network catalyzer for multi-dimensional similarity search by Sablayrolles et al, 2018
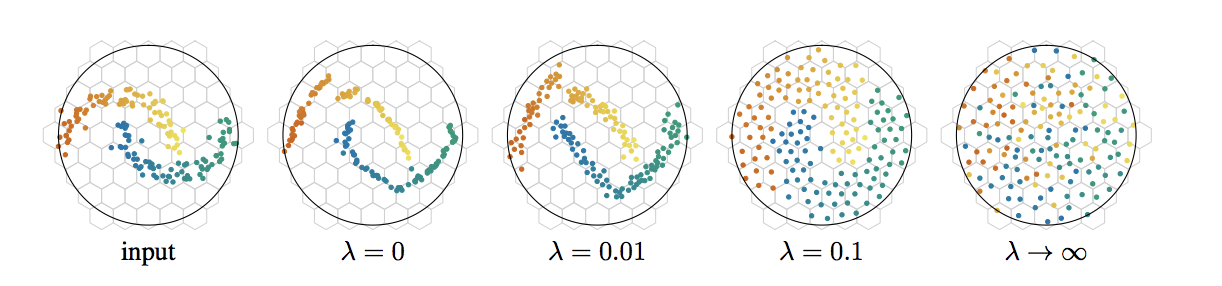
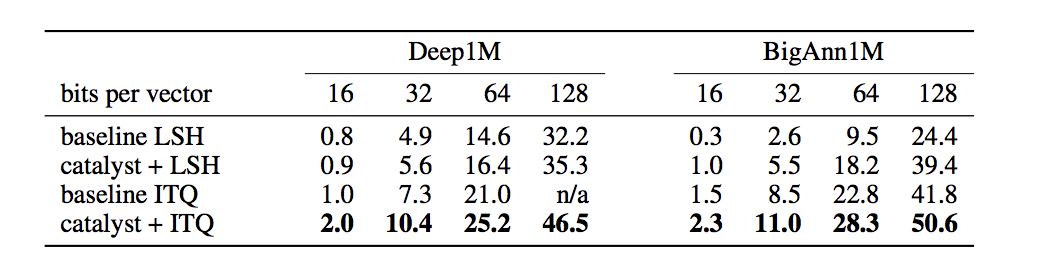
Frequent task in machine learning: finding nearest neighbour of a point in a set.
Much easier if all the points are on a lattice.
Using deep learning, spread out data to have a single point per lattice node while retaining relative position of points.
End-to-end speech recognition
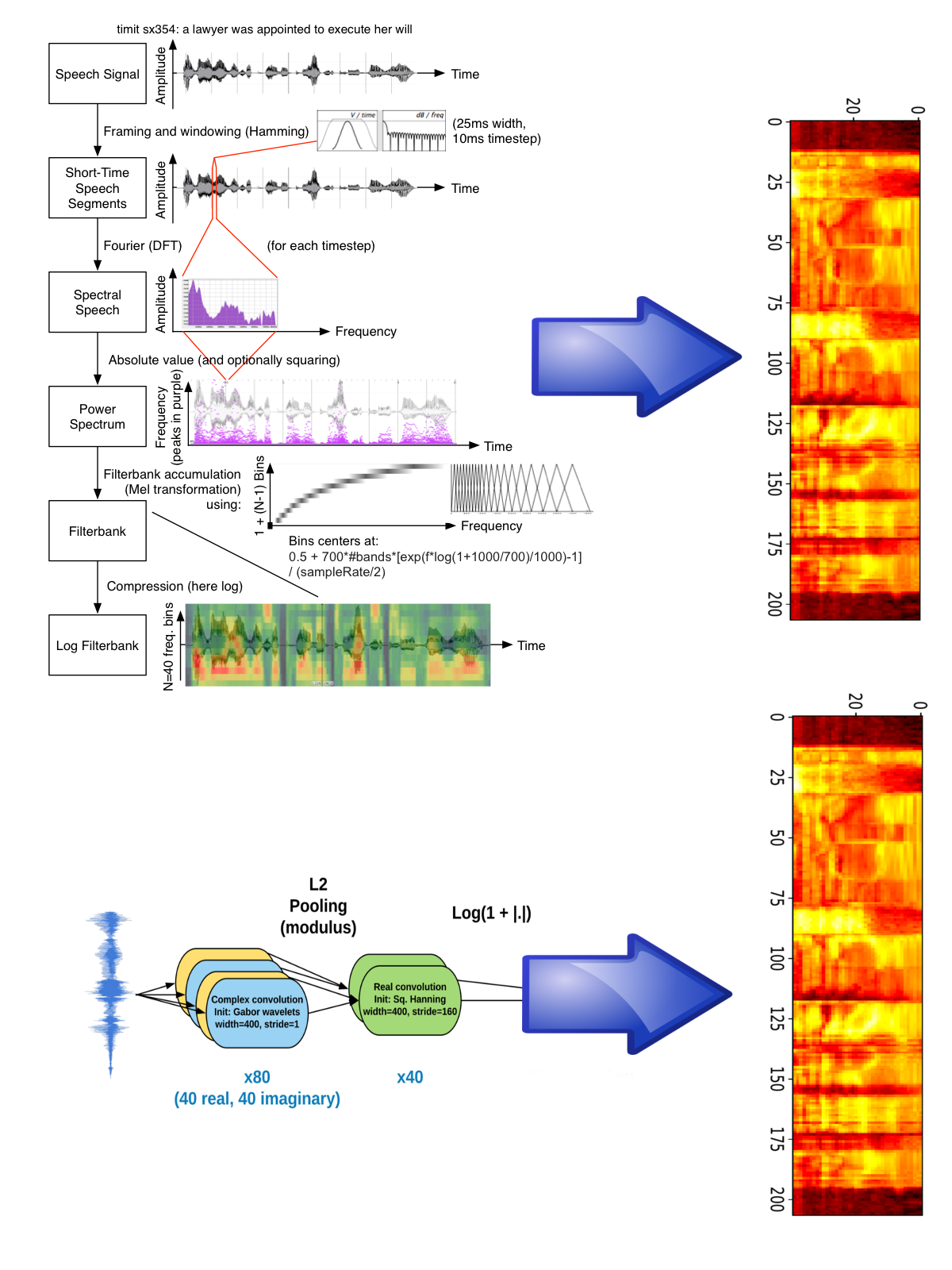
Learning Filterbanks from Raw Speech for Phone Recognition by Zeghidour et al, ICASSP 2018
Computer vision learns from pixel values. Speech still uses hardcoded features based on Fourier transform.
We can replace these features by a learnable architecture. Allows for end-to-end speech recognition from the waveform and outperforms traditionnal features on standard datasets.
Now used for speech pathology detection, speaker identification, etc.
SING: Music note synthesis
SING: Symbol-to-Instrument Neural Generator by Defossez, Zeghidour et al, NIPS 2018
NSynth dataset: 300,000 music notes of 4 seconds each from 1,000 instruments
Given pitch and instrument, generate the waveform (16000 numbers per seconds) for the note.
Able to generalize to unseen combination of pitch and instruments. 40 times faster to train and 2500 faster to evaluate than current state of the art (Wavenet). 70 GB of data generated from 200MB model.
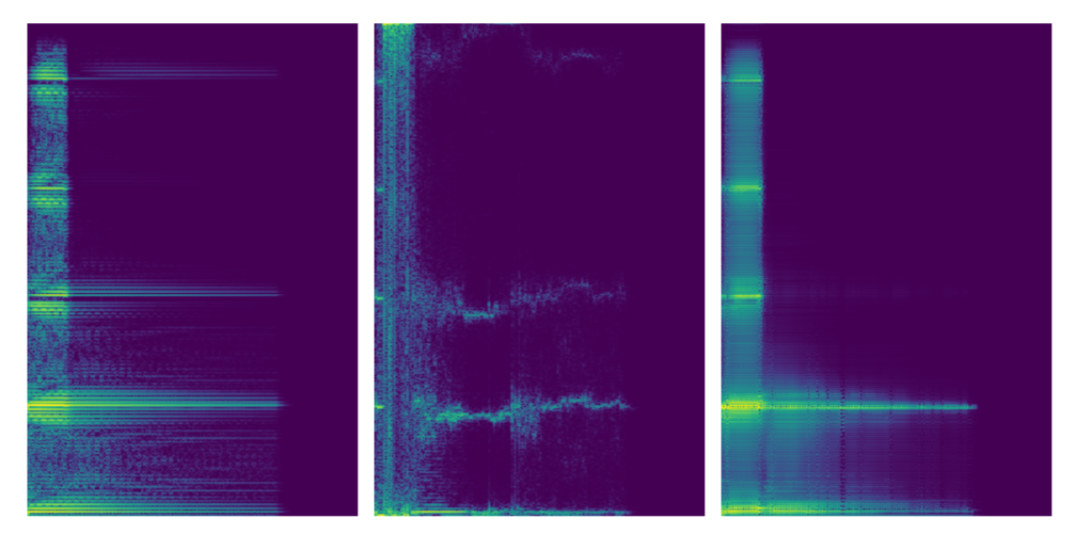

SING: Music note synthesis
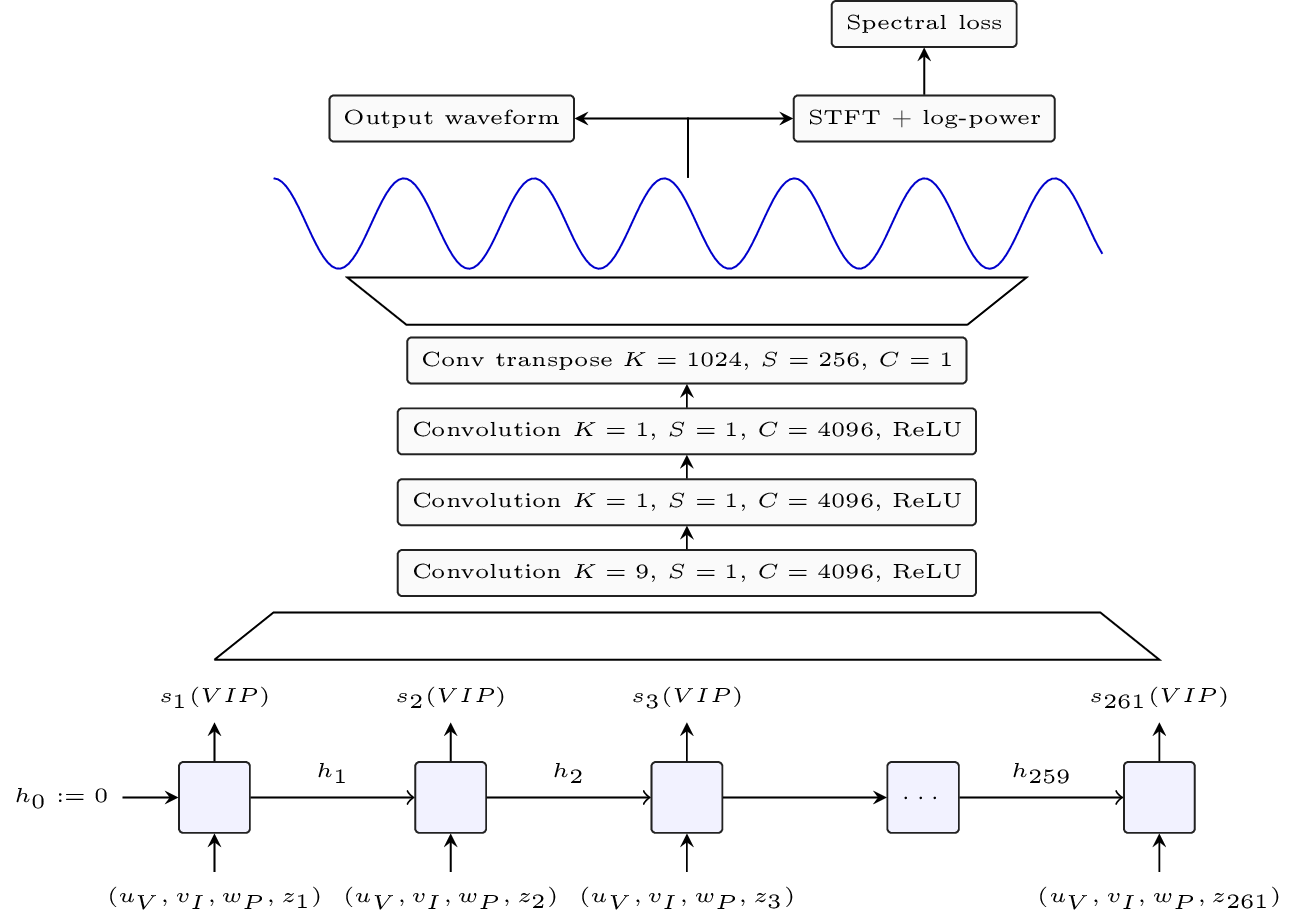
Uses only basic pytorch modules.
LSTM based recurrent network generates sequence of embeddings.
Convolutional decoder turns embeddings into waveform using transposed convolution.
Final loss is computed on log-power spectrogram.
SING: Music note synthesis
| Ground truth | Wavenet | SING | |
| Brass | |||
| Flute | |||
| Organ | |||
| String |
Limit and biases in supervised learning
ConvNets and ImageNet Beyond Accuracy: Understanding Mistakes and Uncovering Biases by Stock et al, ECCV 2018

Accuracy on ImageNet cannot be improved further because of ambigous labels.
Mistakes made by state of the art networks like ResNets are understandable.
Biases are present in datasets and overfitted by deep learning models. Black people doing sports are classified as basketball players.
Reproduction of biases from society in automated system can be detrimental. This is an open topic of research.

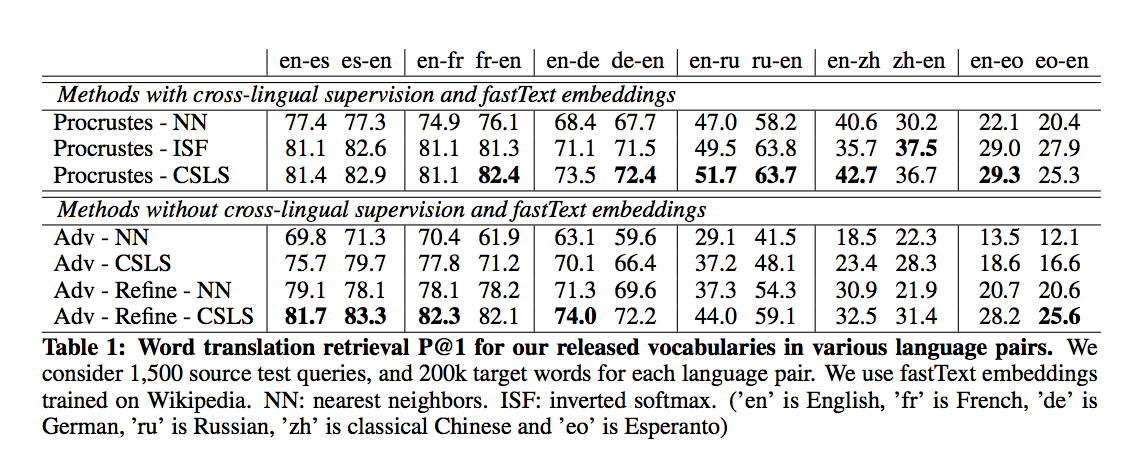
Unsupervised machine learning translation
Word translation without parallel data by Lample, Conneau et al, ICLR 2018
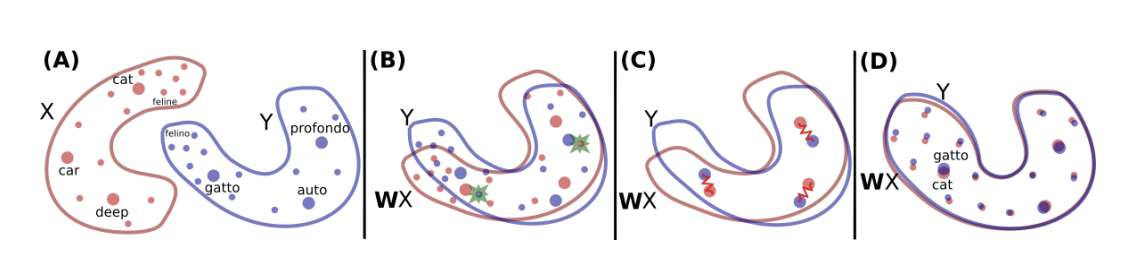
To learn translation from language A to B, requires many pairs (A, B). Here the authors use unaligned corpuses for instance Wikipedia in English and in Chinese.
Each language is embedded in a vector space separately.
A rotation matrix $W$ is learned to make the two clouds of points indistinguishable.
Improved nearest neighbour gives the word translation.
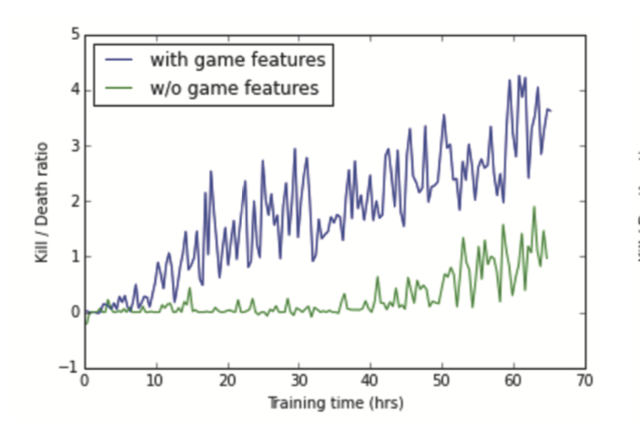
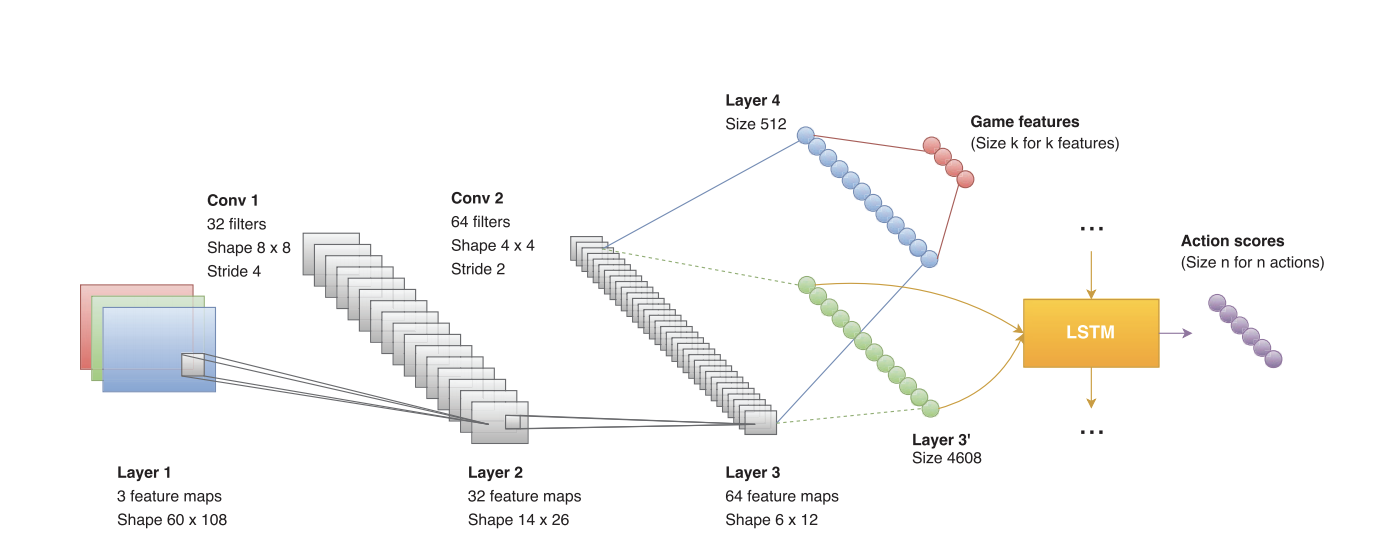
DOOM bot
Playing FPS Games with Deep Reinforcement Learning by Lample et Al, AAAI 2017

Previous works only used screen content as input. Here, authors combine multiple objectives
- predicting next action,
- predicting the presence of objects or enemies.
Learning jointly 1. and 2. improves 1.